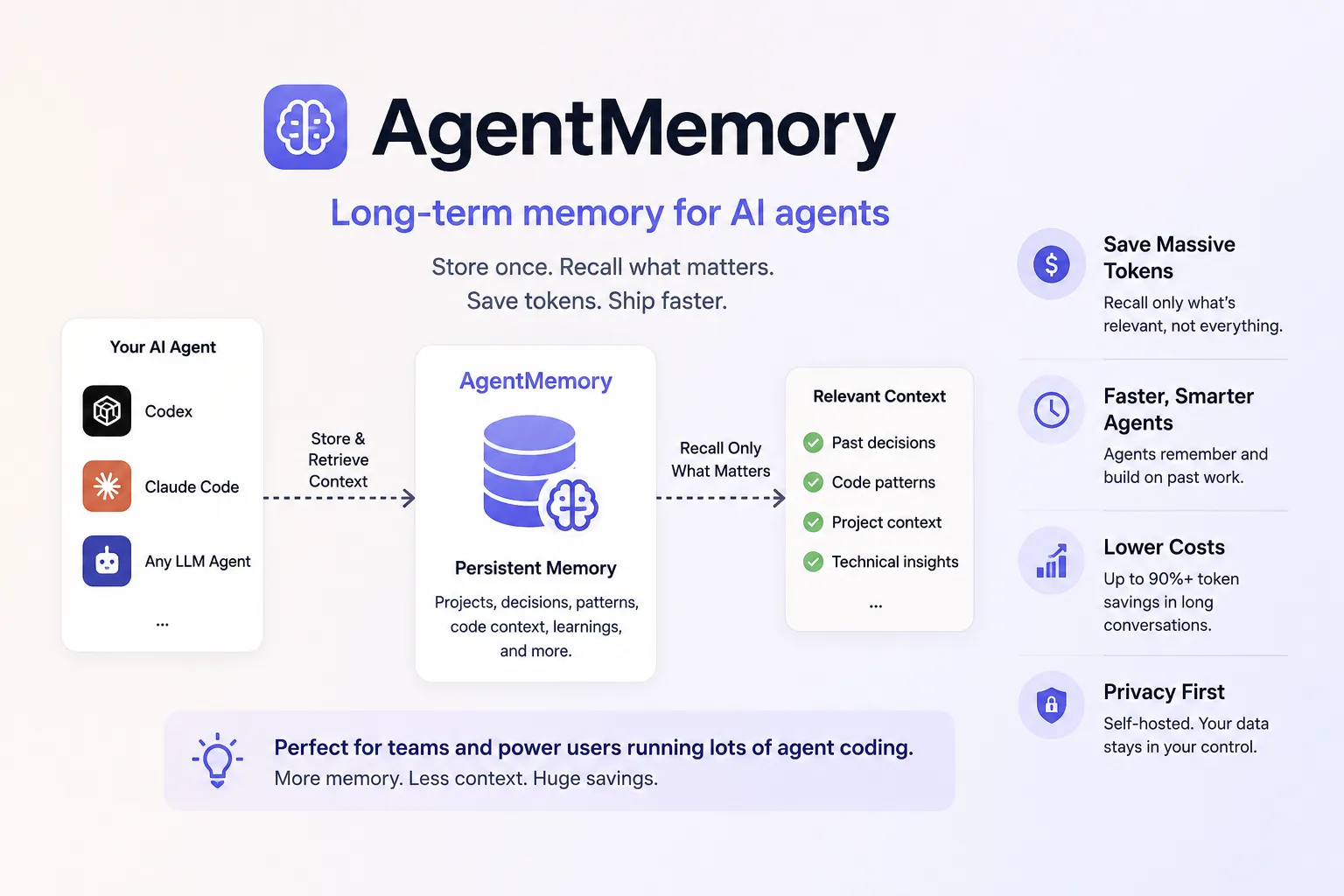
agentmemory is an open-source project that gives AI coding agents persistent, searchable memory across sessions. The repository presents it as a background memory server for tools such as Claude Code, Codex CLI, Cursor, Gemini CLI, OpenCode, Cline, Roo Code, Windsurf, and other clients that can connect through MCP or HTTP.
The practical idea is straightforward: instead of making a developer re-explain a codebase, architectural decision, recurring bug, preferred library, or testing convention at the start of every session, agentmemory records useful observations while the agent works, compresses them into structured memories, and retrieves only the most relevant context when a later session begins.
Why persistent agent memory matters
Coding agents are strongest when they understand the local project: file layout, past decisions, failed attempts, naming conventions, test patterns, deployment constraints, and the developer’s preferences. The problem is that most agent sessions are disposable. Once a chat is gone or compacted, the next agent often starts by rediscovering the same facts.
For people who use Claude Code, Codex CLI, or similar agentic tools heavily, that repetition has two costs. First, it burns human attention because the developer has to restate context. Second, it burns model tokens because the same background material gets pasted, summarized, or reloaded again and again.
agentmemory tries to reduce that waste by moving long-lived project knowledge out of the prompt and into a local memory layer. The agent then asks for a compact, relevant slice of memory instead of receiving the whole history.
How it works in practice
In a normal workflow, agentmemory runs as a local server. The repository describes a command-line setup where the server starts separately, while integrations for Claude Code, Codex CLI, and MCP-capable tools connect to it.
For Claude Code, the project describes a native plugin path with hooks, skills, and MCP wiring. For Codex CLI, it describes a plugin that registers lifecycle hooks such as session start, user prompt submission, tool-use events, pre-compaction, and stop. Other tools can connect through a shared MCP server configuration that points to the running agentmemory server.
Once connected, the memory layer watches the agent’s work. It can capture prompts, tool calls, file access patterns, command results, errors, and session summaries, then turn that raw activity into searchable memory. A later session can recall the relevant pieces: where authentication lives, why a dependency was chosen, which test file covers a behavior, or which bug fix was attempted before.
Where the token savings come from
The savings are not magic; they come from changing the unit of context.
Without a memory system, developers often paste large project notes, old conversation summaries, README excerpts, issue descriptions, and previous debugging traces into every new session. That approach sends broad context to the model whether or not the current task needs it.
agentmemory’s approach is narrower. It stores raw observations, compresses sessions into structured facts, indexes them, and retrieves a small top-K set of relevant memories. The repository describes a default token budget for injected memory, meaning the agent gets a bounded context package rather than an unbounded dump of everything that ever happened.
Conceptually, the saving is achieved by replacing repeated full-context replay with selective recall. Technically, the repository describes a pipeline that deduplicates observations, applies privacy filtering, compresses observations into structured memory, creates embeddings, indexes memories for keyword and vector search, and optionally uses graph extraction. At session start, it builds a project profile, searches across memory streams, and injects only the selected context.
That is especially useful for agent coding because much of the valuable context is stable: project architecture, naming conventions, previous decisions, local test commands, error patterns, and developer preferences. Once stored, those facts do not need to be regenerated or pasted repeatedly.
Capabilities described by the project
The repository describes several building blocks that make agentmemory more than a static notes file:
- Automatic capture through agent hooks, so useful facts can be saved during normal work.
- Hybrid retrieval using keyword search, vector similarity, and optional graph traversal.
- Memory consolidation into working, episodic, semantic, and procedural layers.
- MCP tools such as recall, smart search, file history, session timelines, exports, relation queries, and governance deletion.
- A local viewer for observing memory activity and replaying sessions.
- Local storage and local embedding options for teams or individuals who want to avoid sending every memory operation to an external service.
For heavy users of coding agents, the most important point is cross-session continuity. The same project history can be available whether the next task starts in Claude Code, Codex CLI, Cursor, or another MCP-aware client.
Best-fit scenarios
agentmemory is most compelling when a developer works on the same codebases repeatedly and lets agents perform multi-step edits, debugging, refactoring, or test-driven changes. In that setting, the memory layer can accumulate the kind of context that would otherwise live in a developer’s head or in scattered chat transcripts.
It can also help when several agents or tools touch the same project. A Claude Code session might discover the test structure, a Codex CLI session might later add a related feature, and a different MCP client might query previous decisions. A shared memory server gives those tools a common recall surface.
The advantage is smaller for one-off prompts, disposable experiments, or tiny repositories where the entire project can be understood quickly. The more recurring the work, the more useful persistent memory becomes.
Adoption notes and caveats
The repository presents agentmemory as a developer tool with several moving parts: a Node package, a local memory server, MCP integration, plugins for some agents, and an iii-engine runtime or Docker fallback for the full experience. That is more infrastructure than a simple project note file, so teams should treat setup and maintenance as part of the adoption cost.
Claims about retrieval accuracy and token savings in the repository are useful signals, but they should be read as project-provided benchmarks rather than universal guarantees. Real savings will depend on how often the same context is reused, how cleanly the hooks capture useful information, and whether the retrieved memories are relevant enough to replace manual prompting.
Privacy also deserves attention. The project describes filtering for secrets and private tags, but a memory system that observes prompts, tool calls, and file activity should still be configured carefully, especially around credentials, customer data, proprietary repositories, and team sharing.
Editorial verdict
agentmemory addresses a real pain point in agent-heavy development: repeated context loading. Its strongest idea is not simply “memory”, but memory as a retrieval layer that sits between transient agent sessions and the long-running reality of a software project.
For developers using Claude Code, Codex CLI, or multiple MCP-aware coding tools, the potential benefit is clear. Persistent memory can reduce repeated explanations, preserve decisions across compactions and new sessions, and keep useful project knowledge available without stuffing every conversation with old notes.
The trade-off is operational complexity. Developers who want a zero-configuration assistant may prefer built-in notes or project instructions. Developers who run many agent sessions on serious codebases, however, are exactly the audience most likely to benefit from agentmemory’s approach.
For other approaches to agent memory covered on Synopolis, see claude-mem, which focuses on session memory for Claude Code, and OpenHuman, a personal agent built around an evolving profile of its user.
Primary link
Learn more at: https://github.com/rohitg00/agentmemory